1.12 Linux系统中的软件管理
本文共 3899 字,大约阅读时间需要 12 分钟。
文章目录
Linux中的软件包类型
1.DEB(UBlinux DEBlinux)
2.RPM(redhat centOS fadora) 3.bz2,gz,xz (1)需要源码安装需要编译 (2)绿色软件,直接可用 (3)ntfs-3g_ntfsprogs-2017.3.23.tgz 需要编译 “configure” (4)Firefox-latest-x86_64.tar.bz2 绿色 注意:在rhel8中只能使用绿色软件,源码编译软件和rpm软件
先可以上网 64位,可以shell rpm
shell脚本安装: wget
绿色可以直接使用
【无关:卡机子,F3, killall -9 firefox F5(init 5)】
绿色安装包:不需要安装,可以直接使用脚本就可以
软件包的名称结构
linuxqq_2.0.0-b2-1084_x86_64.rpm
| linuxqq | 2.0.0-b2-1084 | x86 | 64 | rpm |
|---|---|---|---|---|
| 软件名称 | 软件版本 | 软件的授权协议版本 | 软件架构 | 软件类型后缀 |
rpm命令管理软件包
rpm -ivh linuxqq_2.0.0-b2-1084_x86_64.rpm#安装参数组合 -i install -v verbose -h hash

rpm -q linuxqq#查询

rpm -q FluffyMcAwesome-B-6.4.0-11.r19335.x86_64.rpm --scripts#查询软件在安装或卸载过程中的运行脚本,查看安装的动作

rpm -qf /usr/local/bin/qq#查询文件属于哪个安装包

rpm -qc openssh-server#查询配置文件

rpm -qp linuxqq_2.0.0-b2-1084_x86_64.rpm --info#查询软件包的软件信息

rpm -ivh linuxqq_2.0.0-b2-1084_x86_64.rpm --force#强制重新安装#当误删软件的文件时,可以通过这条命令重新安装软件

rpm -e linuxqq_2.0.0-b2-1084_x86_64.rpm#卸载软件
rpm -ql linuxqq_2.0.0-b2-1084_x86_64.rpm#查询软件安装文件列表

sh linuxqq_2.0.0-b2-1084_x86_64.sh#sh直接调用


rpm -Kv linuxqq_2.0.0-b2-1084_x86_64.rpm#检测软件md5校验码,查看安装包是否被篡改
rpm -V linuxqq_2.0.0-b2-1084_x86_64.rpm#检测已安装软件在系统中的文件被修改信息
rpm -a linuxqq_2.0.0-b2-1084_x86_64.rpm#所有
rpm -d linuxqq_2.0.0-b2-1084_x86_64.rpm#说明
rpm -ivh linuxqq_2.0.0-b2-1084_x86_64.rpm --nodeps#忽略依赖性#不解除nodeps,无法使用软件#依赖性:a需要b,b需要c#dnf yum:永久解除依赖性
本地软件仓库的搭建
系统软件仓库的作用:
在系统中对软件进行管理 rpm命令是不能解决依赖关系的 如果需要软件在安装过程中自动解决依赖关系 需要大家系统软件仓库
挂载景象(将iso插入目录)
iso:光盘,相当于U盘
mkdir /westosisomount /redehat .iso /westosiso(挂载)#访问westosiso目录,BaseOS 基础组建,APP 应用软件目录df#查看是否挂载成功
df 的原理
df命令:linux下查看磁盘容量的常用命令。可以列出block数量,总容量,使用率等。
 df :查看磁盘容量
df :查看磁盘容量
| Filesystem | 1k-blocks | Used | Available | Use% | Mounted on |
|---|---|---|---|---|---|
| 磁盘设备 | blocks个数 | 使用的容量 | 有效容量 | 空闲率 | 挂载点 |

搭建本地仓库
#cd /etc/yum.reposvim /etc/yum.repos/westos.repo#先写仓库名:[westosiso]#name=AppStream#挂载的地方:baseurl=file:///westosiso/AppStream#gpgcheck(签证)=0 表示不去检测key,所有第三方软件都可以安装,但损失不负责#gpgcheck=1 表示检测(系统因为该软件BUG出现损失,和厂商无关)#enabled=1(是否使用这个仓库,是)curl file:///westosiso/AppStream#查看地址是否可以访问dnf clean all #清除过去的搜索记录dnf install gcc#从本地仓库下载gccdnf remove gcc#卸载gccdnf repolist#查看仓库列表






开机自启挂载
每次开机,挂载不会自启
将开机自启挂载写入开机自运行脚本
vim /etc/rc.d/rc.local#写入:mount /iso/rhel-8.2-x86_64-dvd.iso /westosisosh /etc/rc.d/rc.local#运行脚本chmod +x /etc/rc.d/rc.local#所有人都可以执行该脚本reboot#重启,测试



删除自启挂载命令
 恢复原始的权限设定
恢复原始的权限设定 
网络软件仓库的搭建
主机里的虚拟机怎么使用主机里的镜像
解决方法:通过http(网页共享),使主机的镜像资源共享
dnf install httpd -y#在真机上安装httpd服务器,它提供超文本传输协议systemctl disable --now firewalld#关闭防火墙systemctl enable --now httpd#打开http服务,其他主机可以通过网页访问这台主机mkdir /var/www/html/westosiso#创建一个共享目录mount /ios//rhel-8.2-x86_64-dvd.iso /var/www/html/westosiso#挂载镜像到共享目录#通过网页去测试,键入:172.25.254.23/westosiso(这台主机的IP地址)#成功vim /etc/yum.repos.d/westos.repo#修改链接地址#baseurl=http://172.25.254.23/westosiso/AppStream#baseurl=http://172.25.254.23/westosiso/BaseOSdnf list httpd#列出httpd软件#测试#在虚拟机的浏览器键入172.25.254.23/westosisoz


 成功打开http服务
成功打开http服务
 搭建网络软件仓库
搭建网络软件仓库  利用httpd搭建网络软件仓库
利用httpd搭建网络软件仓库 
 修改 /etc/yum.repos.d/westos.repo
修改 /etc/yum.repos.d/westos.repo 
 网络软件仓库搭建成功
网络软件仓库搭建成功 
dnf 软件管理命令
dnf 的用法
dnf clean all#删除本地源的信息,方便识别#清除系统中已经加载的仓库缓存信息

dnf list all#列出所有软件

dnf install dhcp-server#安装#dnf install dhcp-server -y#y指的是安装时需要手动输入的yes
安装时,依赖性也一并安装

dnf remove dhcp-server#卸载#dnf remove dhcp-server -y#y指的是卸载时需要手动输入的yes

dnf reinstall dhcp-server#重新安装

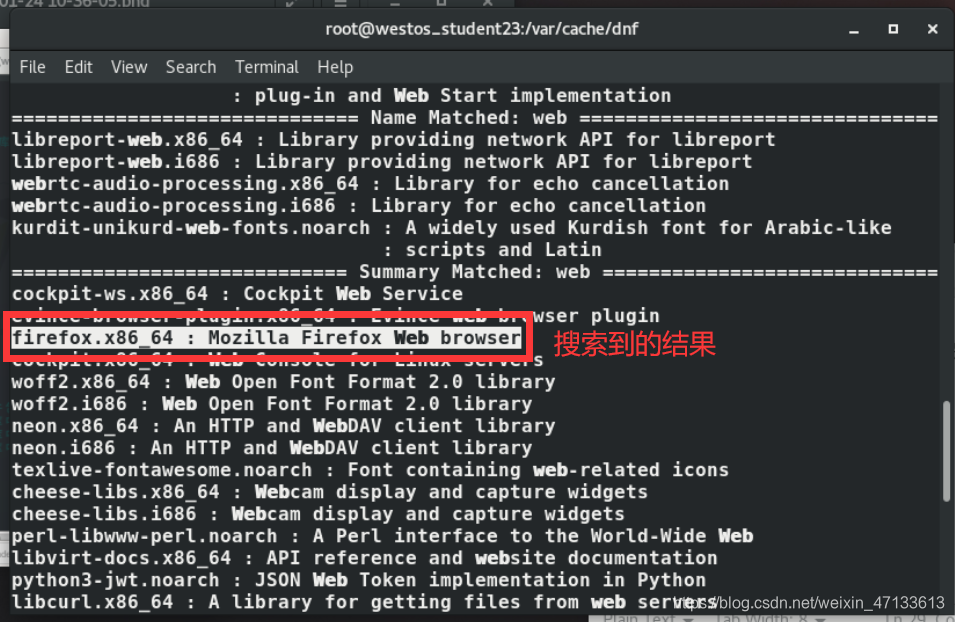
dnf search web#搜索

dnf whatprovides ls#搜索包含ls文件的软件包

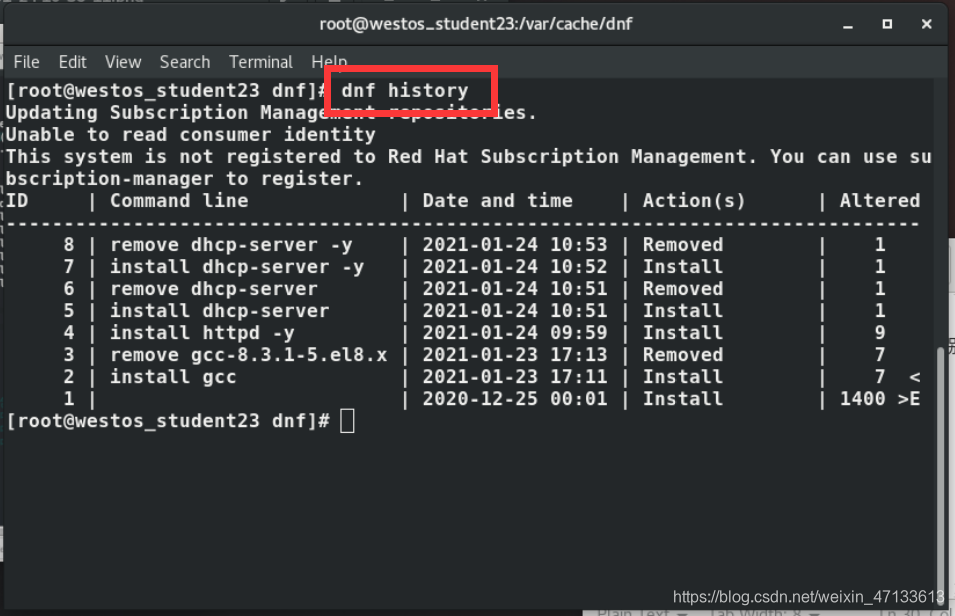
dnf history#列出dnf的执行历史
dnf history info 8#dnf执行历史第8条的详细信息

dnf info dhcp-server#查看dhcp-server的详细信息

dnf group list#列出软件组

dnf group list --hidden#列出隐藏的软件组

dnf group info GNOME#查看GNOME软件组信息

下载仓库的软件包
注意!
是下载,不是安装dnf whatprovides */yumdownloader#用yumdownloader下载软件

yumdownloader httpd#下载仓库中指定软件的安装包到当前目录
yumdownloader 仅仅下载软件安装包,依赖性没有被下载

yumdownloader httpd --destdir=/opt#下载仓库中指定软件的安装包到指定目录

yumdownloader httpd --destdir=/opt --resolve#一并下载依赖性#下载仓库中指定软件安装包和软件依赖性到指定目录

第三方软件仓库的搭建

转载地址:http://yssv.baihongyu.com/
你可能感兴趣的文章